Une hypothèse courante dans l'analyse des séries chronologiques est que les indicateurs étudiés sont stationnaires et pourraient être modélisés par un modèle linéaire. Cela pourrait par exemple suggérer qu'un indicateur suivrait le même type de tendance dans le temps avec quelques fluctuations aléatoires. L'hypothèse d'utiliser des paramètres constants peut toutefois ne pas être réaliste dans la pratique, en particulier sur de longues périodes.
Il est courant d'avoir des séries chronologiques qui présentent un comportement non stationnaire. Par exemple, le produit intérieur brut (PIB) présente souvent une tendance linéaire. Une solution courante consiste à supprimer la tendance par une transformation telle que la différenciation de l'indicateur ou le calcul du taux de croissance.
Certains indicateurs peuvent cependant nécessiter plusieurs différences pour les rendre stationnaires. Ce faisant, leur interprétation intuitive pourrait être perdue ou ne pas être aussi significative, par exemple lorsque l'indicateur est déjà en pourcentage.
Les modèles de paramètres variant dans le temps peuvent faciliter l'hypothèse stricte de paramètres constants et offrir plus de flexibilité. Si le processus sous-jacent suit réellement un processus variant dans le temps, essayer de le modéliser comme s'il s'agissait d'un modèle linéaire constant serait également incorrect.
Il est également courant que de nombreuses variables de séries chronologiques soient hétéroscédastiques, en particulier les variables financières. Les chocs subis par une variable peuvent donc varier avec différentes intensités au fil du temps. [1] [1]. Cela pourrait avoir pour conséquence que les intervalles de prévision soient trompeurs et donc donner des résultats trompeurs.
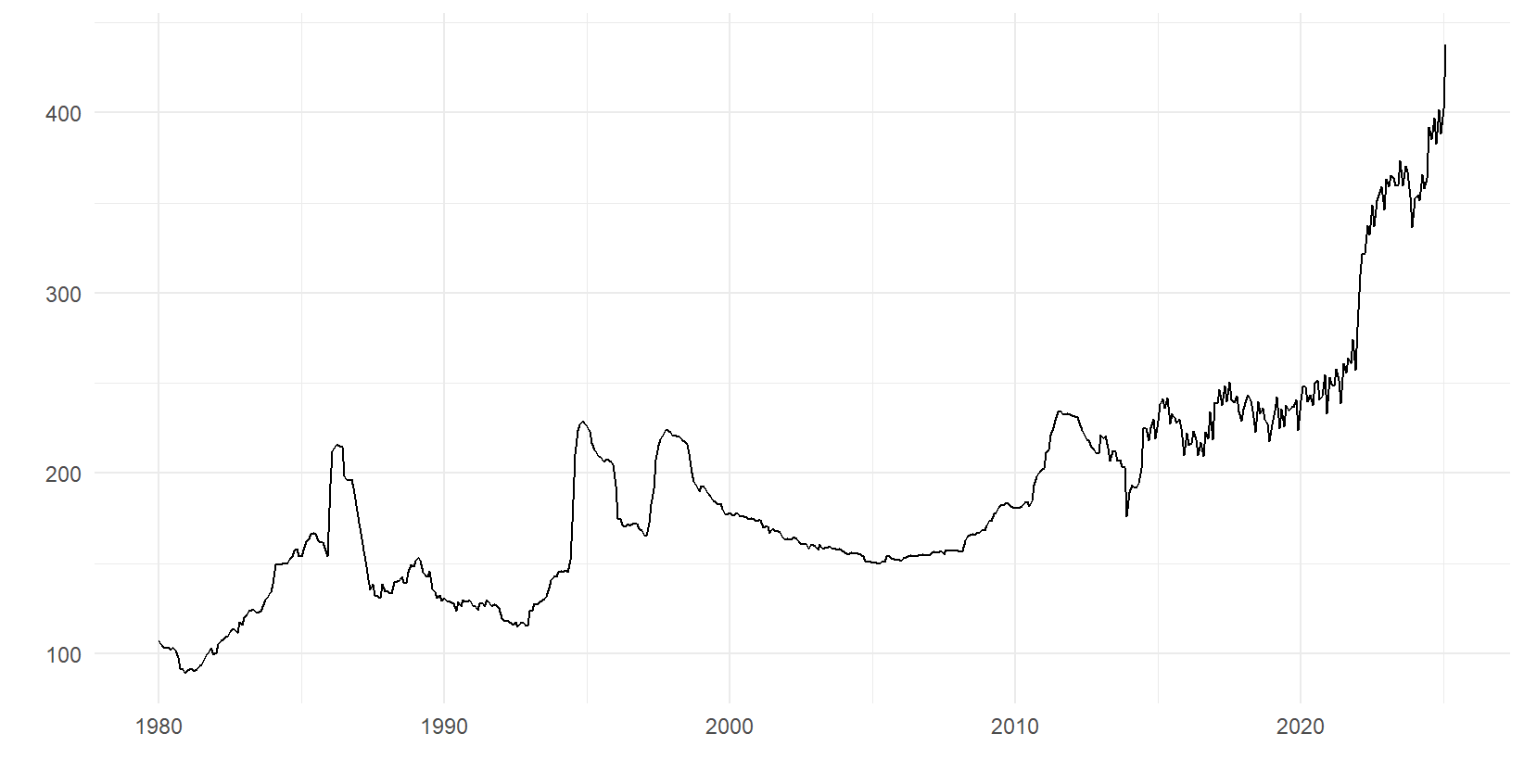
À titre d'illustration, avant de passer au modèle, la figure 1 montre l'indice des prix à la consommation (IPC) suédois entre 1980 et 2025 pour le sous-groupe café, thé et cacao. La variable semble avoir globalement une tendance positive. Les observations semblent fluctuer avec une intensité différente aux alentours de 2014 et au-delà par rapport aux années précédentes. Cela pourrait être un signe d'hétéroscédasticité dans les termes d'erreur.
La figure 2 montre les résultats de différents tests de stationnarité effectués par Indicio. Comme illustré, la variable n'est pas stationnaire en niveaux, mais il est indiqué qu'elle pourrait être stationnaire en effectuant un certain type de transformation. Il semble également y avoir une indication d'une possible hétéroscédasticité et qu'il serait donc préférable de la modéliser avec une volatilité stochastique.

[1] En d'autres termes, la variance des termes d'erreur change au fil du temps.
L'autorégression vectorielle traditionnelle (VAR) avec pp les retards sont de la forme

où ytest un vecteur de K variables endogènes au temps t=1,..., T. Le modèle présenté en (1) émet certaines hypothèses importantes qui peuvent ne pas être valables pour certaines séries chronologiques et peuvent alors entraîner de mauvaises performances prévisionnelles. L'une de ces hypothèses est que les matrices de coefficients VAR UNE1,...,UNEpet la matrice de covariance des chocs Σ sont constants dans le temps. Cela signifie, par exemple, que l'effet d'une variable sur une autre variable reste le même en période de croissance économique rapide et en période de dépression, ce qui n'est peut-être pas réaliste. Le modèle VAR bayésien variable dans le temps (TVP-BVAR) assouplit cette hypothèse et permet aux paramètres du modèle de varier dans le temps.
Le cas hétéroscédastique où la matrice de covariance Σ les changements dans le temps présentent souvent un intérêt particulier car ils permettent à l'ampleur des chocs de varier dans le temps. Cela permet de modéliser regroupement de la volatilité souvent observées dans les données, où des périodes prolongées de forte volatilité sont suivies de périodes plus calmes de faible volatilité. Les modèles dotés d'une matrice de covariance constante peuvent donner de mauvais résultats dans de tels cas, avec des intervalles de prévision trop larges en période de calme et trop étroits en période de tensions économiques. La VAR bayésienne variable dans le temps avec volatilité stochastique présentée ci-dessous permet à la matrice de covariance de variance du terme d'erreur de varier dans le temps et peut donc être mieux adaptée pour gérer des données présentant une hétéroscédasticité.
Le modèle BVAR variable dans le temps (TV-BVAR) est le même modèle que dans (1), mais avec un indice temporel sur les coefficients VAR UNEj,tet la matrice de covariance des chocs σtΣtpour indiquer qu'ils peuvent désormais varier dans le temps.
Il existe trois méthodes principales pour modéliser l'évolution des paramètres au fil du temps :
Cet article wiki décrit le troisième type de modèle d'évolution des paramètres, avec des marches aléatoires.
Le modèle TV-BVAR avec une évolution aléatoire des paramètres de marche peut être écrit de manière compacte sous la forme modèle d'espace d'états (voir les notes techniques dans la section Annexe ou Dieppe et al. (2018)) :

L'équation (2) est appelée équation d'observation, où ytest un vecteur de variables endogènes, c'est-à-dire la variable principale avec les autres indicateurs pendant le temps t. La matrice de conception Xtest composé de toutes les valeurs décalées de yt, éventuellement avec un point d'intersection et des variables exogènes.
Le vecteur β_t est une version empilée des coefficients VAR UNE_1,...,UNE_K, et est appelé latent, non observé, vecteur d'état. Le équation de transition d'état (3) modélise l'évolution du β_t comme une promenade aléatoire. Notez comment βtvarie dans le temps, contrairement à un modèle VAR classique où il serait statique dans le temps. Il a une forme récursive et ne dépend que de l'innovation νtavec une matrice de variance de covariance Ω qui est supposée constante dans le temps. L'implication de Ω être constant, c'est βtévolue au même rythme au fil du temps. Le modèle d'évolution temporelle de la matrice de covariance Σtest décrit ci-dessous.
Pour comprendre l'implication du modèle TV-BVAR, considérez le cas spécial univarié simple suivant du modèle en (2) et (3) sans interception

où βtpourrait être appelée la pente d'une droite de régression, une pente qui change désormais à chaque instant. L'écart le plus important νta, plus le modèle est flexible pour prendre en compte l'évolution des paramètres au fil du temps, mais il est également plus enclin à un surajustement avec des prévisions potentiellement plus mauvaises. Il est possible de trouver le juste équilibre entre flexibilité et risque de surajustement à partir des données en estimant σν2.
Il existe plusieurs manières de modéliser une matrice de covariance variant dans le temps. Le modèle le plus couramment utilisé est basé sur la décomposition

où F est une matrice triangulaire inférieure dont certaines sont en diagonale et Λtest une matrice diagonale où le logarithme des éléments de la diagonale suit chacun son propre processus autorégressif avec un décalage d'un point. Cela a deux implications. Tout d'abord, puisque la matrice F est constante dans le temps, la corrélation entre les variables est considérée comme constante et définie dès le départ. La deuxième implication est que seules les variances sont autorisées à varier dans le temps puisque Λtest libre d'évoluer dans le temps.
L'objectif est de calculer la distribution postérieure de tous les paramètres du modèle

où l'indice 1 :T désigne une séquence temporelle de données ou de paramètres, par exemple β_1 :T désigne tout β_t à partir de t= 1 à t=T. La probabilité ci-dessus est proportionnelle à une distribution normale avec une moyenne β_1 :T et matrice de covariance Σ_1 :T. Le précédent p(β_1 :T∣Ω) est également supposé avoir une distribution normale et Ω suit a priori une distribution inverse de Wishart. Enfin, Σ1 :Tsuit une échelle inverse χ2- distribution.
La solution analytique permettant d'obtenir le postérieur est insoluble et une approche de Monte-Carlo par chaîne de Markov (MCMC) utilisant l'échantillonnage de Gibbs est plutôt utilisée pour simuler des tirages à partir de la distribution postérieure dans (4). Le filtre de Kalman et le lisseur constituent l'algorithme standard pour l'inférence dans les modèles d'espace d'états. Pour les variables variables dans le temps, il a toutefois été démontré qu'un moyen plus efficace d'échantillonner les paramètres variant dans le temps consiste à tirer directement de la distribution normale multivariée de β1 :Tet d'exploiter la parcimonie pour rendre l'échantillonnage très efficace.
Les variables sont d'abord corrigées des variations saisonnières si la saisonnalité est présente. Ensuite, plusieurs modèles VAR tels que (1) sont estimés avec différents décalages. Le nombre de retards par rapport au modèle produisant les plus petits critères d'information d'Akaike (AIC) est ensuite choisi.
Une fois que le nombre de retards à utiliser a été décidé, la VAR bayésienne variable dans le temps est ensuite estimée en utilisant un échantillonnage MCMC de la distribution postérieure dans (4).
Dieppe, A., Legrand, R. et van Roye, B. (2018). Guide technique de la boîte à outils d'estimation, d'analyse et de régression bayésiennes (BEAR). Version 4.2 préliminaire, Banque centrale européenne.
Statistiques de la Suède (2025). Indice des prix à la consommation (IPC) par groupe de produits (coicop), 1980=100. mois 1980m01 - 2025m02. https://www.statistikdatabasen.scb.se/pxweb/en/ssd/START__PR_ _PR0101__PR0101A/KPICOI80MN/. Consulté le 14 mars 2025.

Nous fournissons un logiciel de prévision automatisé qui associe des méthodes académiques de pointe à des indicateurs avancés spécifiques au marché. Cela permet à votre organisation d'atteindre le plus haut niveau de précision des prévisions.
© 2025 Indicio Technologies Tous droits réservés
