Um modelo de correção de erros vetoriais (VECM) pode ser visto como uma extensão de um modelo VAR (consulte Avançado: VAR). Onde um modelo VAR exige que todas as variáveis incluídas sejam estacionárias, um VECM não. Em vez disso, exige que as variáveis sejam cointegradas, o que significa que existe uma combinação linear delas que é estacionária. Assim como em um modelo VAR, incluir um grande número de séries temporais e atrasos aumentará rapidamente o número de parâmetros. O risco então é que o modelo seja superajustado aos dados. O laço do VECM corrige isso aplicando uma penalidade de Lasso aos coeficientes do modelo.
A primeira etapa para ajustar um modelo VECM é determinar se há alguma cointegração presente nos dados. Isso geralmente é feito usando o teste de Johansen, que determina o número de combinações lineares estacionárias. Eles são chamados de vetores de cointegração e o número deles, conforme determinado pelo teste de Johansen, geralmente é indicado com a letra rr. O modelo VECM Lasso amplia isso aplicando o critério de seleção de classificação de Bunea et. al. que é capaz de limitar o número de vetores de cointegração por meio do encolhimento.
No artigo sobre modelos VAR, temos as equações que descrevem cada variável em função de suas próprias defasagens e as defasagens das outras variáveis como

onde os termos de erro θtεté a parte de yto que não é explicado pelo modelo. No modelo existem kk equações, uma para cada variável. Os termos umalsão matrizes contendo os coeficientes de latência l em todas as equações e yté um vetor das observações de todas as variáveis no tempo t.
Em um modelo VECM, o processo VAR é modelado na primeira transformação de diferença das variáveis, indicada δtde cada vez t. O modelo VECM completo agora pode ser escrito como
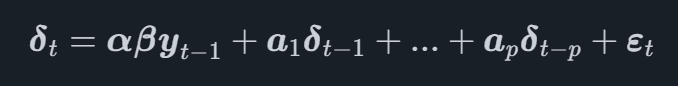
onde β é uma matriz que contém os coeficientes dos vetores de cointegração e αα é uma matriz que contém o ajustamento vetores para os vetores de cointegração.
Estudando a equação, podemos ver que a primeira diferença da série temporal é modelada em função dos vetores de cointegração e das defasagens de cada série temporal.
A principal diferença entre os modelos VECM e VECM Lasso regulares é que o último aplica uma penalidade de Lasso para reduzir os parâmetros para zero, semelhante ao que um modelo VARX Lasso (Avançado: VARX Lasso) faz em comparação com um modelo VAR regular.
Para ajustar um modelo VECM Lasso, a primeira tarefa é selecionar a ordem máxima (ou seja, o número máximo de atrasos) dele. No Indicio, isso é feito ajustando modelos VAR de ordem 1,... , pmax ondep max é o número máximo de atrasos selecionados pelo usuário. É selecionado aquele que melhor se ajusta aos dados de acordo com o Critério de Informação (AIC) de Akaike, o que favorece um modelo simples em relação a um mais complicado, mas ainda é responsável por um bom ajuste do modelo.
Depois que a ordem de defasagem é selecionada, o critério de seleção de classificação de Bunea et. al. é aplicado para determinar a classificação de cointegração rr.
Com esses parâmetros selecionados, a próxima etapa é dividir os dados em duas partes, digamos que temos uma série temporal YY com NN observações. A primeira parte contém as observações 1 para ntrainntrem onde o último é o número de observações usadas para ajustar o modelo inicial, isso é chamado de conjunto de treinamento. A segunda parte contém os dados restantes contendo n observações test=N−ntrain.
A segunda etapa é ajustar modelos usando o conjunto de observações de treinamento para uma variedade de diferentes λ valores. Esses modelos são então usados para criar uma previsão começando no primeiro ponto do conjunto de testes. Os modelos são então ajustados para usar mais uma observação do conjunto de teste durante o ajuste, e uma previsão é feita, começando um ponto mais adiante do que o anterior. Desta forma, um grande número de backtest previsões são criadas para simular a construção de modelos em momentos anteriores e a elaboração de uma previsão.
Comparando as previsões do backtest com o resultado real nos dados, os valores do erro médio de previsão quadrática (MSFE) podem ser calculados para os diferentes valores de λ, fornecendo uma medida do desempenho do modelo em um cenário de previsão, considerando um determinado λ valor.
Com o ideal λ valor selecionado, um modelo final que é ajustado a todos os dados é criado usando esse valor. Isso resulta em um modelo com uma penalidade ajustada para extrair o máximo poder preditivo dos dados, sem sobreajustar o modelo.

Fornecemos software de previsão automatizado que combina métodos acadêmicos de ponta com indicadores líderes específicos do mercado. Isso ajuda sua organização a atingir o mais alto nível de precisão de previsão.
© 2025 Indicio Technologies Todos os direitos reservados
