Model korekcji błędów wektorowych (VECM) może być postrzegany jako rozszerzenie modelu VAR (patrz Zaawansowane: VAR). W przypadku gdy model VAR wymaga, aby wszystkie zawarte zmienne były stacjonarne, VECM nie. Zamiast tego wymaga współzintegrowania zmiennych, co oznacza, że istnieje ich liniowa kombinacja, która jest nieruchoma. Podobnie jak w przypadku modelu VAR, włączenie dużej liczby szeregów czasowych i opóźnień szybko zwiększy liczbę parametrów. Ryzyko staje się wtedy, że model zostanie nadmiernie dopasowany do danych, lasso VECM naprawia to, stosując karę Lasso do współczynników modelu.
Pierwszym krokiem w kierunku dopasowania modelu VECM jest ustalenie, czy w danych występuje jakakolwiek kointegracja. Zwykle odbywa się to za pomocą testu Johansena, który określa liczbę stacjonarnych kombinacji liniowych. Są one określane jako wektory kointegracyjne a ich liczba określona przez test Johansena jest zwykle oznaczana literą rr. Model VECM Lasso rozszerza to, stosując kryterium wyboru rangi Bunea i in., które jest w stanie ograniczyć liczbę wektorów kointegracyjnych poprzez skurcz.
Z artykułu na temat modeli VAR mamy równania, które opisują każdą zmienną jako funkcję jej własnych opóźnień i opóźnień innych zmiennych jako

gdzie terminy błędu εtεtjest częścią ytczego nie wyjaśnia model. W modelu są kk równania, po jednym dla każdej zmiennej. Warunki _lsą macierzami zawierającymi współczynniki w opóźnieniu l we wszystkich równaniach i ytjest wektorem obserwacji wszystkich zmiennych w czasie t.
W modelu VECM proces VAR jest modelowany na pierwszej transformacji różnicowej zmiennych, oznaczonej δtw czasie t. Pełny model VECM można teraz zapisać jako
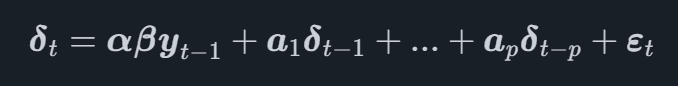
gdzie β jest macierzą zawierającą współczynniki z wektorów kointegracyjnych i αα jest macierzą, która zawiera dostosowanie wektory dla wektorów kointegracyjnych.
Badając równanie, widzimy, że pierwsza różnica szeregów czasowych jest modelowana jako funkcja wektorów kointegracyjnych i opóźnień każdego szeregu czasowego.
Główna różnica między zwykłymi modelami VECM i VECM Lasso polega na tym, że ten ostatni stosuje karę Lasso, aby zmniejszyć parametry do zera, podobnie jak model VARX Lasso (Advanced: VARX Lasso) w przeciwieństwie do zwykłego modelu VAR.
Aby dopasować model VECM Lasso, pierwszym zadaniem jest wybranie jego maksymalnej kolejności (tj. maksymalnej liczby opóźnień). W Indicio odbywa się to poprzez dopasowanie modeli VAR rzędu 1,... , pmax gdziep max to maksymalna liczba opóźnień wybranych przez użytkownika. Wybrano ten, który najlepiej pasuje do danych zgodnie z kryterium informacyjnym Akaike (AIC), co faworyzuje prosty model w porównaniu z bardziej skomplikowanym, ale nadal odpowiada za dobre dopasowanie modelu.
Po wybraniu kolejności opóźnień kryterium wyboru rangi Bunea i in. stosuje się do określenia rangi kointegracji rr.
Po wybraniu tych parametrów następnym krokiem jest podzielenie danych na dwie części, powiedzmy, że mamy szereg czasowy YY z NN obserwacje. Pierwsza część zawiera obserwacje 1 do ntrainnpociąg, w którym ta ostatnia jest liczbą obserwacji użytych do dopasowania do modelu początkowego, nazywa się to zestawem treningowym. Druga część zawiera pozostałe dane zawierające n obserwacji test=n−nTrain.
Drugim krokiem jest dopasowanie modeli z wykorzystaniem zestawu obserwacji treningowych dla szeregu różnych λ wartości. Modele te są następnie wykorzystywane do tworzenia prognozy zaczynającej się od pierwszego punktu zestawu testowego. Modele są następnie dostosowywane tak, aby podczas dopasowywania wykorzystywały jeszcze jedną obserwację zestawu testowego i sporządzana jest prognoza, zaczynając o jeden punkt dalej niż poprzednia. W ten sposób duża liczba test wsteczny tworzone są prognozy, które naśladują budowanie modeli w poprzednich punktach czasu i sporządzanie prognozy.
Porównując prognozy testu wstecznego z rzeczywistym wynikiem w danych, średnie kwadratowe wartości błędu prognozy (MSFE) można obliczyć dla różnych wartości λ, zapewniając miarę tego, jak dobrze model działa w scenariuszu prognozowania, biorąc pod uwagę konkretny λ wartość.
Z optymalnym λ wybrana wartość, przy użyciu tej wartości tworzony jest ostateczny model dopasowany do wszystkich danych. Powoduje to model z karą, która jest dostrojona tak, aby wyodrębnić maksymalną moc predykcyjną danych, bez nadmiernego dopasowania modelu.

Zapewniamy oprogramowanie do automatycznego prognozowania, które łączy najnowocześniejsze metody akademickie z wiodącymi wskaźnikami specyficznymi dla rynku. Dzięki temu Twoja organizacja osiąga najwyższy poziom dokładności prognozowania.
© 2025 Indicio Technologies Wszelkie prawa zastrzeżone
