Ein Vector Error Correction Model (VECM) kann als Erweiterung eines VAR-Modells betrachtet werden (siehe Advanced: VAR). Wenn bei einem VAR-Modell alle enthaltenen Variablen stationär sein müssen, ist dies bei einem VECM nicht der Fall. Stattdessen müssen die Variablen kointegriert werden, was bedeutet, dass eine lineare Kombination von ihnen existiert, die stationär ist. Genau wie bei einem VAR-Modell erhöht das Einbeziehen einer hohen Anzahl von Zeitreihen und Verzögerungen die Anzahl der Parameter schnell. Dann besteht das Risiko, dass das Modell zu stark an die Daten angepasst wird. Das VECM-Lasso behebt dies, indem es eine Lasso-Palenz auf die Koeffizienten des Modells anwendet.
Der erste Schritt zur Anpassung eines VECM-Modells besteht darin, festzustellen, ob in den Daten eine Kointegration vorhanden ist. Dies wird üblicherweise mit dem Johansen-Test durchgeführt, der die Anzahl der stationären Linearkombinationen bestimmt. Diese werden bezeichnet als Kointegrationsvektoren und die Anzahl von ihnen, wie sie durch den Johansen-Test bestimmt wird, wird normalerweise mit dem Buchstaben r bezeichnetr. Das VECM-Lasso-Modell erweitert dies, indem es das Rangauswahlkriterium von Bunea et. al. anwendet, das in der Lage ist, die Anzahl der Kointegrationsvektoren durch Schrumpfung zu begrenzen.
Aus dem Artikel über VAR-Modelle haben wir die Gleichungen, die jede Variable als Funktion ihrer eigenen Verzögerungen und der Verzögerungen der anderen Variablen beschreiben als

wo die Fehlerausdrücke δtαtist der Teil von ytwas durch das Modell nicht erklärt wird. Im Modell gibt es kk Gleichungen, eine für jede Variable. Die Bedingungen einlsind Matrizen, die die Koeffizienten bei Verzögerung enthalten l in allen Gleichungen und ytist ein Vektor der Beobachtungen aller Variablen zu einem Zeitpunkt t.
In einem VECM-Modell wird der VAR-Prozess auf der ersten Differenztransformation der Variablen modelliert, bezeichnet δ.tzur Zeit t. Das vollständige VECM-Modell kann jetzt geschrieben werden als
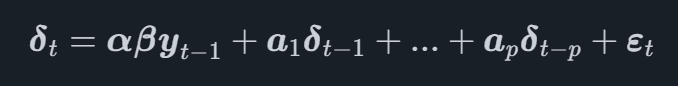
woher β ist eine Matrix, die die Koeffizienten aus den Kointegrationsvektoren und α enthältα ist eine Matrix, die enthält Anpassung Vektoren für die Kointegrationsvektoren.
Wenn wir die Gleichung studieren, können wir sehen, dass der erste Unterschied der Zeitreihen als Funktion der Kointegrationsvektoren und der Verzögerungen jeder Zeitreihe modelliert wird.
Der Hauptunterschied zwischen den regulären VECM- und VECM-Lasso-Modellen besteht darin, dass letzteres eine Lasso-Penalty anwendet, um die Parameter gegen Null zu verkleinern, ähnlich dem, was ein VARX-Lasso-Modell (Advanced: VARX Lasso) im Gegensatz zu einem regulären VAR-Modell tut.
Um ein VECM-Lasso-Modell anzupassen, müssen Sie zunächst die maximale Reihenfolge (d. h. die maximale Anzahl von Verzögerungen) auswählen. In Indicio erfolgt dies durch die Anpassung von VAR-Modellen der Ordnung 1,... , pmax wop max ist die maximale Anzahl von Verzögerungen, die vom Benutzer ausgewählt wurden. Es wird dasjenige ausgewählt, das gemäß Akaikes Informationskriterium (AIC) am besten zu den Daten passt. Dadurch wird ein einfaches Modell einem komplizierteren Modell vorgezogen, aber dennoch eine gute Modellanpassung gewährleistet.
Nachdem die Lag-Reihenfolge ausgewählt wurde, wird das Rangauswahlkriterium von Bunea et. al. angewendet, um den Kointegrationsrang r zu bestimmenr.
Wenn diese Parameter ausgewählt sind, besteht der nächste Schritt darin, die Daten in zwei Teile aufzuteilen, sagen wir, wir haben eine Zeitreihe YY mit NN Beobachtungen. Der erste Teil enthält Beobachtungen 1 zum Trainingntrainieren, wobei letzteres die Anzahl der Beobachtungen ist, die zur Anpassung an das ursprüngliche Modell verwendet wurden. Dies wird als Trainingssatz bezeichnet. Der zweite Teil enthält die verbleibenden Daten, die n test=N−NTRAIN Beobachtungen enthalten.
Der zweite Schritt besteht darin, Modelle unter Verwendung des Trainingssatzes von Beobachtungen für eine Reihe verschiedener λ Werte. Diese Modelle werden dann verwendet, um eine Prognose zu erstellen, die am ersten Punkt im Testsatz beginnt. Die Modelle werden dann angepasst, um bei der Anpassung eine weitere Beobachtung des Testsatzes zu verwenden, und es wird eine Prognose erstellt, die einen Punkt weiter vorne beginnt als der vorherige. Auf diese Weise entsteht eine große Anzahl von Backtest Es werden Prognosen erstellt, die Gebäudemodelle zu früheren Zeitpunkten emulieren und eine Prognose erstellen.
Beim Vergleich der Backtest-Prognosen mit dem tatsächlichen Ergebnis in den Daten können die Werte für den mittleren quadratischen Prognosefehler (MSFE) für die verschiedenen Werte von berechnet werden λ, das ein Maß dafür liefert, wie gut das Modell in einem Prognoseszenario unter bestimmten Bedingungen abschneidet λ Wert.
Mit dem optimalen λ Wenn Sie einen Wert ausgewählt haben, wird ein endgültiges Modell, das an alle Daten angepasst ist, mit diesem Wert erstellt. Das Ergebnis ist ein Modell mit einem Nachteil, das darauf abgestimmt ist, die maximale Vorhersagefähigkeit der Daten zu extrahieren, ohne das Modell zu überfordern.

Wir bieten automatisierte Prognosesoftware, die modernste akademische Methoden mit marktspezifischen Frühindikatoren kombiniert. Dies hilft Ihrem Unternehmen, ein Höchstmaß an Prognosegenauigkeit zu erreichen.
© 2025 Indicio Technologies Alle Rechte vorbehalten
