Un Vector Error Correction Model (VECM) può essere visto come un'estensione di un modello VAR (vedi Avanzato: VAR). Se un modello VAR richiede che tutte le variabili incluse siano stazionarie, un VECM no. Richiede invece che le variabili siano cointegrate, il che significa che esiste una combinazione lineare di esse che è stazionaria. Proprio come per un modello VAR, l'inclusione di un numero elevato di serie temporali e ritardi aumenterà rapidamente il numero di parametri. Il rischio diventa quindi che il modello venga adattato eccessivamente ai dati. Il lazo VECM risolve questo problema applicando una penalità Lazo ai coefficienti del modello.
Il primo passo per adattare un modello VECM è determinare se è presente una cointegrazione nei dati. Questo viene fatto comunemente usando il test di Johansen che determina il numero di combinazioni lineari stazionarie. Queste sono denominate vettori di cointegrazione e il loro numero determinato dal test di Johansen è solitamente indicato con la lettera rr. Il modello VECM Lasso estende questa situazione applicando il criterio di selezione dei ranghi di Bunea et. al. che è in grado di limitare il numero di vettori di cointegrazione attraverso il restringimento.
Dall'articolo sui modelli VAR abbiamo le equazioni che descrivono ogni variabile in funzione dei propri ritardi e i ritardi delle altre variabili come

dove i termini di errore αtεtfa parte di ytche non è spiegato dal modello. Nel modello ci sono kk equazioni, una per ogni variabile. I termini unlsono matrici contenenti i coefficienti in ritardo l in tutte le equazioni e ytè un vettore delle osservazioni di tutte le variabili contemporaneamente t.
In un modello VECM, il processo VAR è modellato sulla prima trasformazione differenziale delle variabili, indicata Δtal momento t. Il modello VECM completo può ora essere scritto come
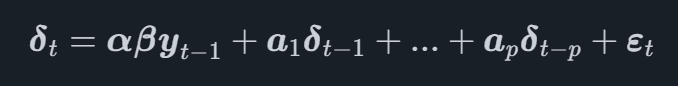
dove β è una matrice che contiene i coefficienti dei vettori di cointegrazione e αα è una matrice che contiene regolazione vettori per i vettori di cointegrazione.
Studiando l'equazione possiamo vedere che la prima differenza delle serie temporali è modellata in funzione dei vettori di cointegrazione e dei ritardi di ciascuna serie temporale.
La differenza principale tra i normali modelli VECM e VECM Lasso è che quest'ultimo applica una penalità Lasso per ridurre i parametri verso lo zero, in modo simile a ciò che fa un modello VARX Lasso (Advanced: VARX Lasso) rispetto a un normale modello VAR.
Per adattare un modello VECM Lasso, il primo compito è selezionarne l'ordine massimo (cioè il numero massimo di ritardi). In Indicio questo viene fatto adattando i modelli VAR di ordine 1,... , pmax dovep max è il numero massimo di ritardi selezionati dall'utente. Viene selezionato quello che meglio si adatta ai dati secondo l'Information Criterion (AIC) di Akaike. Ciò favorisce un modello semplice rispetto a uno più complicato, ma rappresenta comunque un buon adattamento del modello.
Dopo aver selezionato l'ordine di ritardo, viene applicato il criterio di selezione del rango di Bunea et. al. per determinare il grado di cointegrazione rr.
Con questi parametri selezionati, il passaggio successivo consiste nel dividere i dati in due parti, supponiamo di avere una serie temporale YY con NN osservazioni. La prima parte contiene le osservazioni da 1 a ntrainntreno in cui quest'ultimo è il numero di osservazioni utilizzate per adattarsi al modello iniziale, questo è chiamato set di addestramento. La seconda parte contiene i dati rimanenti contenenti n osservazioni test=n−ntrain.
Il secondo passaggio consiste nell'adattare i modelli utilizzando il set di osservazioni di addestramento per una serie di diversi λ valori. Questi modelli vengono quindi utilizzati per creare una previsione a partire dal primo punto del set di test. I modelli vengono quindi adattati per utilizzare un'altra osservazione del set di test durante l'adattamento e viene fatta una previsione partendo di un punto più avanti rispetto al precedente. In questo modo un gran numero di test retrospettivo vengono create previsioni che emulano modelli di costruzione in momenti precedenti e fanno una previsione.
Confrontando le previsioni del back-test con il risultato effettivo dei dati, è possibile calcolare i valori dell'errore quadratico medio di previsione (MSFE) per i diversi valori di λ, fornendo una misura delle prestazioni del modello in uno scenario previsionale dato uno specifico λ valore.
Con l'ottimale λ valore selezionato, un modello finale adattato a tutti i dati viene creato utilizzando quel valore. Il risultato è un modello con una penalizzazione ottimizzata per estrarre la massima potenza predittiva dei dati, senza adattare eccessivamente il modello.

Forniamo un software di previsione automatizzato che unisce metodi accademici all'avanguardia con indicatori principali specifici del mercato. Questo aiuta la tua organizzazione a raggiungere il massimo livello di precisione delle previsioni.
© 2025 Indicio Technologies Tutti i diritti riservati
