Un modelo vectorial de corrección de errores (VECM) puede verse como una extensión de un modelo VAR (consulte Avanzado: VAR). Cuando un modelo VAR requiere que todas las variables incluidas sean estacionarias, un VECM no lo hace. En cambio, requiere que las variables estén cointegradas, lo que significa que existe una combinación lineal de ellas que es estacionaria. Al igual que en un modelo VAR, incluir un número elevado de series temporales y desfases aumentará rápidamente el número de parámetros. Se corre entonces el riesgo de que el modelo se ajuste demasiado a los datos. El lazo VECM soluciona este problema aplicando una penalización por efecto de lazo a los coeficientes del modelo.
El primer paso para ajustar un modelo VECM es determinar si hay alguna cointegración presente en los datos. Esto se hace normalmente mediante la prueba de Johansen, que determina el número de combinaciones lineales estacionarias. Estas se denominan vectores de cointegración y el número de ellos determinado por la prueba de Johansen se suele indicar con la letra rr. El modelo VECM Lasso amplía esto al aplicar el criterio de selección por rangos de Bunea et. al., que puede limitar el número de vectores de cointegración mediante la contracción.
Del artículo sobre modelos VAR tenemos las ecuaciones que describen cada variable en función de sus propios rezagos y los rezagos de las demás variables como

donde los términos de error τtωtes parte de ytlo cual no se explica en el modelo. En el modelo hay kk ecuaciones, una para cada variable. Los términos unlson matrices que contienen los coeficientes de desfase l en todas las ecuaciones y ytes un vector de las observaciones de todas las variables a la vez t.
En un modelo VECM, el proceso VAR se modela según la primera transformación por diferencias de las variables, denominada δta la vez t. El modelo VECM completo ahora se puede escribir como
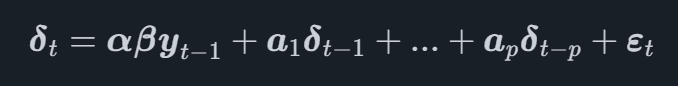
donde β es una matriz que contiene los coeficientes de los vectores de cointegración y αα es una matriz que contiene el ajuste vectores para los vectores de cointegración.
Al estudiar la ecuación podemos ver que la primera diferencia de la serie temporal se modela en función de los vectores de cointegración y los rezagos de cada serie temporal.
La principal diferencia entre los modelos VECM y VECM Lasso normales es que este último aplica una penalización de lazo para reducir los parámetros a cero, similar a lo que hace un modelo VARX Lasso (Avanzado: VARX Lasso) en comparación con un modelo VAR normal.
Para adaptarse a un modelo VECM Lasso, la primera tarea es seleccionar el orden máximo (es decir, el número máximo de retrasos) del mismo. En Indicio, esto se hace ajustando modelos VAR de orden 1,... , pmax dondep max es el número máximo de retrasos seleccionado por el usuario. Se selecciona el que mejor se ajusta a los datos según el Criterio de Información (AIC) de Akaike, lo que favorece un modelo simple en lugar de uno más complicado, pero aun así tiene en cuenta un buen ajuste del modelo.
Una vez seleccionado el orden de retraso, se aplica el criterio de selección de rango de Bunea et. al. para determinar el rango de cointegración rr.
Con estos parámetros seleccionados, el siguiente paso es dividir los datos en dos partes, digamos que tenemos una serie temporal YY con NN observaciones. La primera parte contiene las observaciones 1 para ntrain.ncuando este último es el número de observaciones utilizadas para ajustar el modelo inicial, esto se denomina conjunto de entrenamiento. La segunda parte contiene los datos restantes, que contienen n observaciones de test=n−nTRAIN.
El segundo paso es ajustar los modelos utilizando el conjunto de observaciones de entrenamiento para una serie de diferentes λ valores. Luego, estos modelos se utilizan para crear una previsión a partir del primer punto del conjunto de prueba. Luego, los modelos se ajustan para utilizar una observación más del conjunto de prueba al ajustarlos, y se hace una previsión, partiendo un punto más adelantado en el tiempo que el anterior. De esta forma, un gran número de prueba retrospectiva se crean pronósticos que emulan la construcción de modelos en momentos anteriores y la creación de un pronóstico.
Al comparar las previsiones de las pruebas retrospectivas con el resultado real de los datos, se pueden calcular los valores del error medio cuadrático de pronóstico (MSFE) para los diferentes valores de λ, que proporciona una medida del rendimiento del modelo en un escenario de pronóstico dado un λ valor.
Con lo óptimo λ valor seleccionado, se crea un modelo final que se ajusta a todos los datos utilizando ese valor. Esto da como resultado un modelo con una penalización que se ajusta para extraer el máximo poder predictivo de los datos, sin sobreajustar el modelo.

Ofrecemos un software de pronóstico automatizado que combina métodos académicos de vanguardia con indicadores líderes específicos del mercado. Esto ayuda a su organización a alcanzar el nivel más alto de precisión en las previsiones.
© 2025 Iindicio Technologies Todos los derechos reservados
