Een Vector Error Correction Model (VECM) kan worden gezien als een uitbreiding van een VAR-model (zie Geavanceerd: VAR). Waar een VAR-model vereist dat alle opgenomen variabelen stationair zijn, doet een VECM dat niet. In plaats daarvan moeten de variabelen onderling worden geïntegreerd, wat betekent dat er een lineaire combinatie bestaat die stationair is. Net als bij een VAR-model, met een groot aantal tijdreeksen en vertragingen, zal het aantal parameters snel toenemen. Het risico bestaat dan dat het model te veel wordt aangepast aan de gegevens, de VECM-lasso corrigeert dit door een Lasso-straf toe te passen op de coëfficiënten van het model.
De eerste stap om een VECM-model aan te passen is om te bepalen of er sprake is van co-integratie in de gegevens. Dit wordt gewoonlijk gedaan met behulp van de Johansen-test, die het aantal stationaire lineaire combinaties bepaalt. Deze worden aangeduid als co-integratievectoren en het aantal ervan, zoals bepaald door de Johansen-test, wordt meestal aangeduid met de letter rr. Het VECM Lasso-model breidt dit uit door het Bunea et. al. rangselectiecriterium toe te passen, dat in staat is om het aantal co-integratievectoren te beperken door middel van krimp.
Uit het artikel over VAR-modellen hebben we de vergelijkingen waarin elke variabele wordt beschreven als een functie van zijn eigen vertragingen en de vertragingen van de andere variabelen als

waarbij de fouttermenμtis het onderdeel van ytwat niet door het model wordt verklaard. In het model zijn er kk vergelijkingen, één voor elke variabele. De voorwaarden eenlzijn matrices die de coëfficiënten bij vertraging bevatten l in alle vergelijkingen en ytis een vector van de waarnemingen van alle variabelen tegelijk t.
In een VECM-model wordt het VAR-proces gemodelleerd op basis van de eerste verschiltransformatie van de variabelen, aangeduid b1top het moment t. Het volledige VECM-model kan nu worden geschreven als
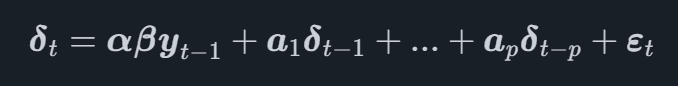
waar β is een matrix die de coëfficiënten bevat van de co-integratievectoren en αα is een matrix die de aanpassing vectoren voor de co-integratievectoren.
Als we de vergelijking bestuderen, kunnen we zien dat het eerste verschil van de tijdreeks wordt gemodelleerd als een functie van de co-integratievectoren en de vertragingen van elke tijdreeks.
Het belangrijkste verschil tussen de reguliere VECM- en VECM Lasso-modellen is dat de laatste een Lasso-straf toepast om de parameters naar nul te verlagen, vergelijkbaar met wat een VARX Lasso-model (Advanced: VARX Lasso) doet in tegenstelling tot een gewoon VAR-model.
Om in een VECM Lasso-model te passen, is de eerste taak het selecteren van de maximale volgorde (d.w.z. het maximale aantal vertragingen) ervan. In Indicio wordt dit gedaan door VAR-modellen van order 1 te monteren,... , pmax waarp max is het maximale aantal vertragingen dat door de gebruiker is geselecteerd. Het model dat het beste bij de gegevens past volgens het informatiecriterium (AIC) van Akaike is geselecteerd. Dit geeft de voorkeur aan een eenvoudig model boven een ingewikkelder model, maar zorgt nog steeds voor een goede pasvorm van het model.
Nadat de lag-volgorde is geselecteerd, wordt het rangselectiecriterium Bunea et. al. toegepast om de co-integratierang r te bepalenr.
Als deze parameters zijn geselecteerd, is de volgende stap om de gegevens in twee delen te splitsen, bijvoorbeeld dat we een tijdreeks Y hebbenY met NN observaties. Het eerste deel bevat observaties 1 om te trainenntrein waarbij dit laatste het aantal waarnemingen is dat is gebruikt om in het oorspronkelijke model te passen, dit wordt de trainingsset genoemd. Het tweede deel bevat de resterende gegevens die n test=N−nTrain-waarnemingen bevatten.
De tweede stap is het aanpassen van modellen met behulp van de trainingsset van observaties voor een reeks verschillende λ waarden. Deze modellen worden vervolgens gebruikt om een voorspelling te maken vanaf het eerste punt in de testset. De modellen worden vervolgens aangepast om bij de aanpassing nog één waarneming van de testset te gebruiken, en er wordt een voorspelling gemaakt, waarbij een punt verder in de tijd wordt begonnen dan het vorige. Op deze manier een groot aantal backtest er worden voorspellingen gemaakt die bouwmodellen op eerdere tijdstippen nabootsen en een voorspelling maken.
Door de prognoses voor de backtest te vergelijken met de werkelijke uitkomst in de gegevens, kunnen de gemiddelde kwadratische voorspellingsfoutwaarden (MSFE) worden berekend voor de verschillende waarden van λ, dat een maatstaf geeft voor hoe goed het model presteert in een voorspellingsscenario, gegeven een specifiek λ waarde.
Met de optimale λ geselecteerde waarde, met behulp van die waarde wordt een definitief model gemaakt dat aan alle gegevens is aangepast. Dit resulteert in een model met een penalty dat is afgestemd om de maximale voorspellende kracht uit de gegevens te halen, zonder het model te veel aan te passen.

We bieden geautomatiseerde voorspellingssoftware die geavanceerde academische methoden combineert met marktspecifieke toonaangevende indicatoren. Dit helpt uw organisatie om het hoogste niveau van voorspellingsnauwkeurigheid te bereiken.
© 2025 Indicio Technologies Alle rechten voorbehouden
