Un modèle de correction d'erreur vectorielle (VECM) peut être considéré comme une extension d'un modèle VAR (voir Avancé : VAR). Lorsqu'un modèle VAR nécessite que toutes les variables incluses soient stationnaires, ce n'est pas le cas d'un VECM. Au lieu de cela, il faut que les variables soient cointégrées, ce qui signifie qu'il existe une combinaison linéaire stationnaire de celles-ci. Tout comme pour un modèle VAR, inclure un nombre élevé de séries chronologiques et des décalages augmentera rapidement le nombre de paramètres. Le risque devient alors que le modèle soit surajusté aux données, le lasso VECM y remédie en appliquant une pénalité de Lasso aux coefficients du modèle.
La première étape pour ajuster un modèle VECM consiste à déterminer s'il existe une cointégration dans les données. Cela se fait généralement à l'aide du test de Johansen qui détermine le nombre de combinaisons linéaires stationnaires. Ils sont appelés vecteurs de cointégration et leur nombre tel que déterminé par le test de Johansen est généralement désigné par la lettre rr. Le modèle VECM Lasso étend cela en appliquant le critère de sélection des rangs de Bunea et al., qui permet de limiter le nombre de vecteurs de cointégration par rétrécissement.
Dans l'article sur les modèles VAR, nous avons les équations qui décrivent chaque variable en fonction de ses propres décalages et les décalages des autres variables comme

où les termes d'erreur « t »εtfait partie de ytce qui n'est pas expliqué par le modèle. Dans le modèle, il y a kk équations, une pour chaque variable. Les termes unlsont des matrices contenant les coefficients en retard l dans toutes les équations et ytest un vecteur des observations de toutes les variables au temps t.
Dans un modèle VECM, le processus VAR est modélisé sur la première transformation différentielle des variables, notée δtà l'heure t. Le modèle VECM complet peut désormais être écrit sous la forme
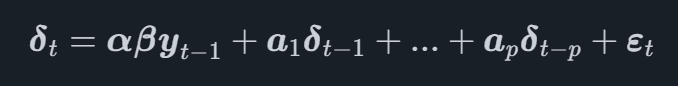
où β est une matrice qui contient les coefficients des vecteurs de cointégration et αα est une matrice qui contient le ajustement vecteurs pour les vecteurs de cointégration.
En étudiant l'équation, nous pouvons voir que la première différence de la série chronologique est modélisée en fonction des vecteurs de cointégration et des décalages de chaque série chronologique.
La principale différence entre les modèles VECM classiques et VECM Lasso est que ce dernier applique une pénalité de Lasso pour ramener les paramètres à zéro, comme le fait un modèle VARX Lasso (Advanced : VARX Lasso) par rapport à un modèle VAR normal.
Pour adapter un modèle VECM Lasso, la première tâche consiste à sélectionner l'ordre maximum (c'est-à-dire le nombre maximum de retards) de celui-ci. Dans Indicio, cela se fait en ajustant les modèles VAR d'ordre 1,... , pmax oùp max est le nombre maximum de décalages sélectionnés par l'utilisateur. Celui qui correspond le mieux aux données selon le critère d'information (AIC) d'Akaike est sélectionné, ce qui favorise un modèle simple par rapport à un modèle plus complexe, tout en tenant compte d'un bon ajustement du modèle.
Une fois l'ordre de décalage sélectionné, le critère de sélection du rang de Bunea et al. est appliqué pour déterminer le rang de cointégration rr.
Une fois ces paramètres sélectionnés, l'étape suivante consiste à diviser les données en deux parties, disons que nous avons une série chronologique YY avec NN observations. La première partie contient les observations 1 pour formerntrain où ce dernier est le nombre d'observations utilisées pour ajuster le modèle initial, c'est ce que l'on appelle l'ensemble d'apprentissage. La deuxième partie contient les données restantes contenant n observations Test=N−nTrain.
La deuxième étape consiste à ajuster les modèles à l'aide de l'ensemble d'observations d'entraînement pour un éventail de λ valeurs. Ces modèles sont ensuite utilisés pour créer une prévision à partir du premier point de la série de tests. Les modèles sont ensuite ajustés pour utiliser une observation supplémentaire de l'ensemble de tests lors de l'ajustement, et une prévision est établie, en commençant un point plus loin dans le temps que le précédent. De cette façon, un grand nombre de rétro-test des prévisions sont créées pour émuler des modèles de construction à des moments antérieurs et établir une prévision.
En comparant les prévisions des tests rétroactifs avec les résultats réels des données, des valeurs d'erreur de prévision quadratique moyenne (MSFE) peuvent être calculées pour les différentes valeurs de λ, fournissant une mesure des performances du modèle dans un scénario de prévision donné λ valeur.
Avec la solution optimale λ valeur sélectionnée, un modèle final adapté à toutes les données est créé à l'aide de cette valeur. Il en résulte un modèle avec une pénalité qui est réglé pour extraire le maximum de puissance prédictive des données, sans surajuster le modèle.

Nous fournissons un logiciel de prévision automatisé qui associe des méthodes académiques de pointe à des indicateurs avancés spécifiques au marché. Cela permet à votre organisation d'atteindre le plus haut niveau de précision des prévisions.
© 2025 Indicio Technologies Tous droits réservés
