Il modello Mixed Data Sampling (MIDAS) è uno dei modelli a frequenza mista disponibili in Indicio.
Quando si prevede una serie temporale più lenta, ad esempio mensile, trimestrale o annuale, può essere un grande vantaggio utilizzare indicatori ad alta frequenza per fornire informazioni più aggiornate su come sta accadendo nell'economia.
Ad esempio, supponiamo di voler prevedere il PIL che è disponibile solo un determinato numero di giorni dopo ogni trimestre. Potremmo avere indici azionari e altri indicatori pubblicati su base giornaliera, settimanale o mensile. Se ci avviciniamo alla fine del trimestre, avremo a disposizione molti dati che descrivono cosa è successo nel primo trimestre che vogliamo prevedere. Un modello a frequenza mista come MIDAS è in grado di utilizzare insieme queste serie temporali di frequenza variabile per creare una previsione della variabile di interesse.
Il modello MIDAS più elementare è quello denominato MIDAS senza restrizioni, che nel caso di una variabile principale trimestrale con un unico indicatore mensile assumerà la forma
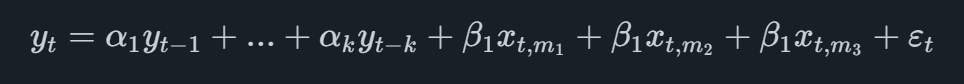
dove la variabile indicatore ha il pedice t,midove misi riferisce alla prima osservazione mensile disponibile. Ad esempio, se dovessimo prevedere il secondo trimestre e avessimo dati mensili dell'indicatore disponibili fino a maggio, aggiungeremmo all'equazione le osservazioni di marzo, aprile e maggio.
In alcuni casi possiamo avere una variabile principale trimestrale o addirittura annuale e forse indicatori settimanali o addirittura giornalieri. Ciò si traduce in un numero molto elevato di parametri da stimare, il che può rendere le stime instabili e aumentare il rischio di un adattamento eccessivo del modello ai dati. Il modello MIDAS risolve questo problema utilizzando una funzione di ritardo polinomiale.
Una funzione di ritardo polinomiale è una funzione che può produrre un output molto flessibile ma ha un numero limitato di parametri. Se abbiamo 30 ritardi nella mappatura di un indicatore giornaliero su una variabile principale mensile, il polinomio consente al modello di utilizzare solo un piccolo numero di parametri flessibili che possono creare una funzione da cui estrarre i singoli parametri giornalieri. Ciò fa sì che i parametri seguano una forma più o meno uniforme.
La spiegazione intuitiva del perché funziona è che se abbiamo un indicatore giornaliero che ha un piccolo effetto all'inizio del mese e un effetto maggiore alla fine, il polinomio sarà in grado di creare un insieme uniforme di parametri che iniziano in basso e aumentano con l'avvicinarsi della fine del mese.

Forniamo un software di previsione automatizzato che unisce metodi accademici all'avanguardia con indicatori principali specifici del mercato. Questo aiuta la tua organizzazione a raggiungere il massimo livello di precisione delle previsioni.
© 2025 Indicio Technologies Tutti i diritti riservati
