Le modèle MIDAS (Mixed Data Sampling) est l'un des modèles à fréquences mixtes disponibles dans Indicio.
Lors de la prévision d'une série chronologique à évolution plus lente, telle qu'une série mensuelle, trimestrielle ou annuelle, il peut être très avantageux d'utiliser des indicateurs à haute fréquence pour fournir des informations plus à jour sur l'évolution de l'économie.
Supposons, par exemple, que nous souhaitions prévoir le PIB, qui ne soit disponible qu'un certain nombre de jours après chaque trimestre. Nous pouvons avoir des indices boursiers et d'autres indicateurs publiés sur une base quotidienne, hebdomadaire ou mensuelle. Si nous approchons de la fin du trimestre, nous disposerons de nombreuses données décrivant ce qui s'est passé au cours du premier trimestre que nous voulons prévoir. Un modèle de fréquence mixte tel que MIDAS est capable d'utiliser ensemble ces séries chronologiques de fréquence variable pour créer une prévision de la variable d'intérêt.
Le modèle MIDAS le plus élémentaire est celui appelé MIDAS sans restriction qui, dans le cas d'une variable principale trimestrielle avec un seul indicateur mensuel, prendra la forme
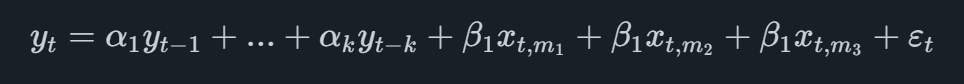
où la variable indicatrice a l'indice t,mioù mifait référence à la ième dernière observation mensuelle disponible. Par exemple, si nous devions prévoir le deuxième trimestre et que les données mensuelles de l'indicateur étaient disponibles jusqu'en mai, nous ajouterions les observations de mars, avril et mai dans l'équation.
Dans certains cas, nous pouvons avoir une variable principale trimestrielle ou même annuelle, et peut-être des indicateurs hebdomadaires ou même quotidiens. Il en résulte un très grand nombre de paramètres à estimer, ce qui peut à la fois rendre les estimations instables et augmenter le risque de surajustement du modèle aux données. Le modèle MIDAS y remédie en utilisant une fonction de décalage polynomiale.
Une fonction de décalage polynomiale est une fonction qui peut produire une sortie très flexible mais qui possède un petit nombre de paramètres. Si nous avons 30 retards lors de la mise en correspondance d'un indicateur quotidien avec une variable principale mensuelle, le polynôme permet au modèle d'utiliser simplement un petit nombre de paramètres flexibles qui peuvent créer une fonction à partir de laquelle les paramètres quotidiens individuels peuvent être extraits. Il en résulte que les paramètres suivent une forme plus ou moins lisse.
L'explication intuitive de la raison pour laquelle cela fonctionne est que si nous avons un indicateur quotidien qui a un effet faible au début du mois et un effet plus important à la fin du mois, le polynôme sera en mesure de créer un ensemble fluide de paramètres qui commencent bas et augmentent à l'approche de la fin du mois.

Nous fournissons un logiciel de prévision automatisé qui associe des méthodes académiques de pointe à des indicateurs avancés spécifiques au marché. Cela permet à votre organisation d'atteindre le plus haut niveau de précision des prévisions.
© 2025 Indicio Technologies Tous droits réservés
