Model próbkowania danych mieszanych (MIDAS) jest jednym z modeli częstotliwości mieszanych dostępnych w Indicio.
Prognozując wolniej poruszające się szeregi czasowe, takie jak miesięczne, kwartalne lub roczne, wielką korzyścią może być użycie wskaźników wysokiej częstotliwości w celu dostarczenia bardziej aktualnych informacji o tym, jak dzieje się w gospodarce.
Na przykład powiedzmy, że chcemy prognozować PKB, który jest dostępny tylko określoną liczbę dni po każdym kwartale. Możemy mieć indeksy giełdowe i inne wskaźniki, które są publikowane codziennie, tygodniowo lub miesięcznie. Jeśli zbliżamy się do końca kwartału, będziemy mieli wiele dostępnych danych, które opisują, co wydarzyło się w pierwszym kwartale, który chcemy przewidzieć. Model częstotliwości mieszanej, taki jak MIDAS, jest w stanie wykorzystać te szeregi czasowe o różnej częstotliwości razem, aby stworzyć prognozę interesującej zmiennej.
Najbardziej podstawowym modelem MIDAS jest ten określany jako MIDAS Unlimited, który w przypadku kwartalnej zmiennej głównej z pojedynczym wskaźnikiem miesięcznym przyjmie formę
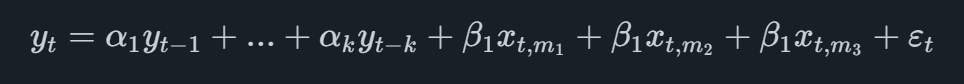
gdzie zmienna wskaźnikowa ma indeks dolny t,migdzie miodnosi się do ostatniej dostępnej miesięcznej obserwacji. Na przykład, gdybyśmy mieli prognozować II kwartał i mamy miesięczne dane wskaźnika dostępne do maja, dodalibyśmy do równania obserwacje z marca, kwietnia i maja.
W niektórych przypadkach możemy mieć kwartalną lub nawet roczną zmienną główną, a być może wskaźniki tygodniowe lub nawet dzienne. Powoduje to bardzo dużą liczbę parametrów do oszacowania, co może zarówno sprawić, że szacunki będą niestabilne, jak i zwiększać ryzyko nadmiernego dopasowania modelu do danych. Model MIDAS naprawia to za pomocą funkcji opóźnienia wielomianowego.
Funkcja opóźnienia wielomianowego to funkcja, która może wytwarzać bardzo elastyczne wyjście, ale ma niewielką liczbę parametrów. Jeśli mamy 30 opóźnień podczas mapowania dziennego wskaźnika do miesięcznej zmiennej głównej, wielomian pozwala modelowi po prostu zastosować niewielką liczbę elastycznych parametrów, które mogą stworzyć funkcję, z której można wyodrębnić poszczególne parametry dzienne. Powoduje to uzyskanie parametrów o mniej lub bardziej gładkim kształcie.
Intuicyjne wyjaśnienie, dlaczego to działa, polega na tym, że jeśli mamy dzienny wskaźnik, który ma niewielki efekt na początku miesiąca i większy efekt na końcu, wielomian będzie w stanie stworzyć płynny zestaw parametrów, które zaczynają się nisko i rosną wraz z zbliżaniem się końca miesiąca.

Zapewniamy oprogramowanie do automatycznego prognozowania, które łączy najnowocześniejsze metody akademickie z wiodącymi wskaźnikami specyficznymi dla rynku. Dzięki temu Twoja organizacja osiąga najwyższy poziom dokładności prognozowania.
© 2025 Indicio Technologies Wszelkie prawa zastrzeżone
