Model lasso do próbkowania mieszanych danych (MIDAS Lasso) jest jednym z modeli mieszanych częstotliwości dostępnych w Indicio.
Prognozując wolniej poruszające się szeregi czasowe, takie jak miesięczne, kwartalne lub roczne, wielką korzyścią może być użycie wskaźników wysokiej częstotliwości w celu dostarczenia bardziej aktualnych informacji o tym, jak dzieje się w gospodarce.
Najbardziej podstawowym modelem MIDAS jest ten określany jako MIDAS Unlimited, który w przypadku kwartalnej zmiennej głównej z pojedynczym wskaźnikiem miesięcznym przyjmie formę
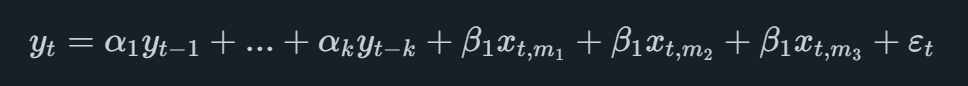
gdzie zmienna wskaźnikowa ma indeks dolny t,migdzie miodnosi się do ostatniej dostępnej miesięcznej obserwacji. Na przykład, gdybyśmy mieli prognozować II kwartał i mamy miesięczne dane wskaźnika dostępne do maja, dodalibyśmy do równania obserwacje z marca, kwietnia i maja.
W niektórych przypadkach możemy mieć kwartalną lub nawet roczną zmienną główną, a być może wskaźniki tygodniowe lub nawet dzienne. Powoduje to bardzo dużą liczbę parametrów do oszacowania, co może zarówno sprawić, że szacunki będą niestabilne, jak i zwiększać ryzyko nadmiernego dopasowania modelu do danych. Model MIDAS Lasso rozwiązuje to, stosując karę Lasso podczas dopasowywania modelu.
Matematycznie kara Lasso jest terminem, który jest dodawany do funkcji, która jest zoptymalizowana podczas dopasowania modelu, dla ogólnego modelu regresji z pp współczynniki można zapisać jako
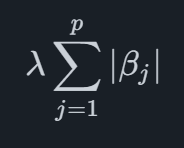
gdzie βjoznacza współczynnik j. Suma wszystkich wartości bezwzględnych współczynników jest sumowana, a następnie suma ta jest skalowana o wartość λ. Powoduje to zmniejszenie szacunków parametrów do zera (a niektórych parametrów dokładnie do zera), co oznacza, że uzyskamy bardziej rzadki i konserwatywny model.
Pierwszym krokiem w kierunku dopasowania modelu MIDAS Lasso jest podzielenie danych na dwie części, które są określane jako zestaw treningowy i zestaw testowy.
Drugim krokiem jest dopasowanie modelu przy użyciu zestawu obserwacji treningowych dla szeregu różnych λ wartości. Modele te są następnie wykorzystywane do tworzenia prognoz dla punktów czasowych w zestawie testowym. Proces ten jest powtarzany wielokrotnie, a średni błąd prognozy jest używany jako miara tego, jak dobrze działa model, biorąc pod uwagę różne wartości λ. Z tego wybierana jest najlepsza wartość dająca najdokładniejsze prognozy.
Z optymalnym λ wybrana wartość, przy użyciu tej wartości tworzony jest ostateczny model dopasowany do wszystkich danych. Powoduje to model z karą, która jest dostrojona tak, aby wyodrębnić maksymalną moc predykcyjną danych, bez nadmiernego dopasowania modelu.

Zapewniamy oprogramowanie do automatycznego prognozowania, które łączy najnowocześniejsze metody akademickie z wiodącymi wskaźnikami specyficznymi dla rynku. Dzięki temu Twoja organizacja osiąga najwyższy poziom dokładności prognozowania.
© 2025 Indicio Technologies Wszelkie prawa zastrzeżone
