Het Mixed Data Sampling Lasso (MIDAS Lasso) -model is een van de modellen met gemengde frequentie die beschikbaar zijn in Indicio.
Bij het voorspellen van een langzamere tijdreeks, zoals een maandelijkse, driemaandelijkse of jaarlijkse reeks, kan het een groot voordeel zijn om hoogfrequente indicatoren te gebruiken om meer actuele informatie te geven over hoe wat er in de economie gebeurt.
Het meest basale MIDAS-model is het model dat wordt aangeduid als Unrestricted MIDAS, dat in het geval van een driemaandelijkse hoofdvariabele met een enkele maandelijkse indicator de vorm aanneemt
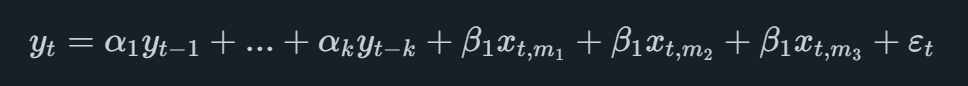
waarbij de indicatorvariabele het subscript heeft t,miwaar miverwijst naar de laatste maandelijkse waarneming die beschikbaar is. Als we bijvoorbeeld het tweede kwartaal zouden voorspellen en we tot mei maandelijkse gegevens van de indicator beschikbaar hebben, zouden we de waarnemingen van maart, april en mei bij de vergelijking optellen.
In sommige gevallen hebben we misschien een hoofdvariabele per kwartaal of zelfs een jaar, en misschien wekelijkse of zelfs dagelijkse indicatoren. Dit resulteert in een zeer groot aantal parameters die moeten worden geschat, waardoor de schattingen instabiel kunnen worden en het risico kan toenemen dat het model te veel wordt aangepast aan de gegevens. Het MIDAS Lasso-model lost dit op door een Lasso-penalty toe te passen bij de montage van het model.
Wiskundig gezien is de Lasso-straf een term die wordt toegevoegd aan de functie die is geoptimaliseerd wanneer het model wordt aangepast, voor een algemeen regressiemodel met pp coëfficiënten het kan worden geschreven als
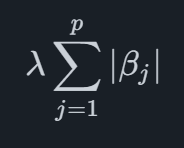
waar βjgeeft de j'th-coëfficiënt aan. De som van alle absolute waarden van de coëfficiënten wordt opgeteld, en vervolgens wordt deze som geschaald met de waarde van λ. Dit heeft tot gevolg dat de parameterschattingen naar nul worden teruggebracht (en sommige parameters tot exact nul), wat betekent dat we een schaarser en conservatiever model zullen krijgen.
De eerste stap bij het aanpassen van een MIDAS Lasso-model is het splitsen van de gegevens in twee delen, die de trainingsset en de testset worden genoemd.
De tweede stap is om het model aan te passen met behulp van de trainingsset van observaties voor een reeks verschillende λ waarden. Deze modellen worden vervolgens gebruikt om voorspellingen te maken voor de tijdstippen in de testset. Dit proces wordt meerdere keren herhaald en de gemiddelde voorspellingsfout wordt gebruikt als maatstaf voor hoe goed het model presteert bij verschillende waarden van λ. Hieruit wordt de beste waarde geselecteerd die de meest nauwkeurige voorspellingen geeft.
Met de optimale λ geselecteerde waarde, met behulp van die waarde wordt een definitief model gemaakt dat aan alle gegevens is aangepast. Dit resulteert in een model met een penalty dat is afgestemd om de maximale voorspellende kracht uit de gegevens te halen, zonder het model te veel aan te passen.

We bieden geautomatiseerde voorspellingssoftware die geavanceerde academische methoden combineert met marktspecifieke toonaangevende indicatoren. Dit helpt uw organisatie om het hoogste niveau van voorspellingsnauwkeurigheid te bereiken.
© 2025 Indicio Technologies Alle rechten voorbehouden
