Le modèle Mixed Data Sampling Sparse Group Lasso (MIDAS Sparse Group Lasso) est l'un des modèles à fréquences mixtes disponibles dans Indicio. Il est similaire au modèle MIDAS Lasso, mais au lieu d'utiliser la pénalité de Lasso de base, il utilise un Lasso à groupe clairsemé adapté à la structure des données.
Lors de la prévision d'une série chronologique à évolution plus lente, telle qu'une série mensuelle, trimestrielle ou annuelle, il peut être très avantageux d'utiliser des indicateurs à haute fréquence pour fournir des informations plus à jour sur l'évolution de l'économie.
Le modèle MIDAS le plus élémentaire est celui appelé MIDAS sans restriction qui, dans le cas d'une variable principale trimestrielle avec un seul indicateur mensuel, prendra la forme
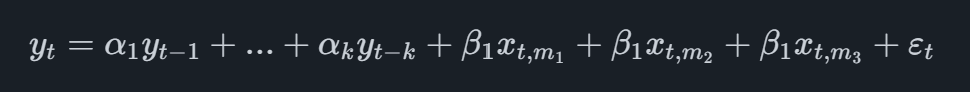
où la variable indicatrice a l'indice t,mioù mimifait référence à la ième dernière observation mensuelle disponible. Par exemple, si nous devions prévoir le deuxième trimestre et que les données mensuelles de l'indicateur étaient disponibles jusqu'en mai, nous ajouterions les observations de mars, avril et mai dans l'équation.
Dans certains cas, nous pouvons avoir une variable principale trimestrielle ou même annuelle, et peut-être des indicateurs hebdomadaires ou même quotidiens. Il en résulte un très grand nombre de paramètres à estimer, ce qui peut à la fois rendre les estimations instables et augmenter le risque de surajustement du modèle aux données. Le modèle MIDAS Sparse Group Lasso résout ce problème en appliquant une pénalité Group Lasso lors de l'ajustement du modèle.
Mathématiquement, la pénalité Lasso Sparse Group est un terme qui est ajouté à la fonction qui est optimisé lors de l'ajustement du modèle, pour un modèle de régression général avec pp coefficients, il peut être écrit sous la forme
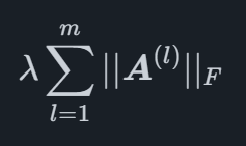
où etX2 est le Frobenius norme de X qui est défini comme

pour une matrice X, où la trace est la somme des entrées diagonales d'une matrice carrée. L'avantage de ce type de pénalité est qu'il permet de réduire à zéro des groupes entiers de coefficients, laissant les autres groupes avec des valeurs non nulles. Pour le Lasso à groupes clairsemés MIDAS, il est utilisé pour pouvoir pénaliser tous les retards de variables spécifiques en tant que groupes, permettant au modèle de sélectionner l'effet optimal qu'une variable spécifique devrait avoir sur la variable principale.
La première étape pour ajuster un modèle MIDAS Sparse Group Lasso consiste à diviser les données en deux parties, appelées ensemble d'apprentissage et ensemble de test.
La deuxième étape consiste à ajuster le modèle à l'aide de l'ensemble d'observations d'entraînement pour un éventail de λ valeurs. Ces modèles sont ensuite utilisés pour créer des prévisions pour les points temporels de l'ensemble de tests. Ce processus est répété plusieurs fois et l'erreur de prévision moyenne est utilisée pour mesurer les performances du modèle en fonction de différentes valeurs de λ. À partir de là, la meilleure valeur donnant les prévisions les plus précises est sélectionnée.
Avec la solution optimale λ valeur sélectionnée, un modèle final adapté à toutes les données est créé à l'aide de cette valeur. Il en résulte un modèle avec une pénalité qui est réglé pour extraire le maximum de puissance prédictive des données, sans surajuster le modèle.

Nous fournissons un logiciel de prévision automatisé qui associe des méthodes académiques de pointe à des indicateurs avancés spécifiques au marché. Cela permet à votre organisation d'atteindre le plus haut niveau de précision des prévisions.
© 2025 Indicio Technologies Tous droits réservés
