O modelo Mixed Data Sparse Group Lasso (MIDAS Sparse Group Lasso) é um dos modelos de frequência mista disponíveis no Indicio. É semelhante ao modelo MIDAS Lasso, mas em vez de usar a penalidade básica do Lasso, está usando um grupo esparso Lasso, que é adaptado à estrutura dos dados.
Ao prever uma série temporal mais lenta, como mensal, trimestral ou anual, pode haver um grande benefício em usar indicadores de alta frequência para fornecer informações mais atualizadas sobre o que está acontecendo na economia.
O modelo MIDAS mais básico é o denominado MIDAS Irrestrito, que, no caso de uma variável principal trimestral com um único indicador mensal, assumirá a forma
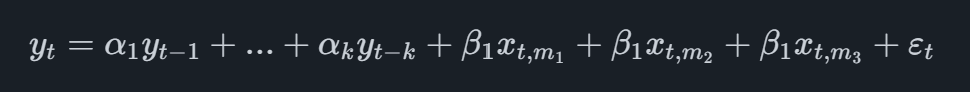
onde a variável indicadora tem o subscrito t,mionde eumiestá se referindo à última observação mensal disponível. Por exemplo, se fizéssemos uma previsão do segundo trimestre e tivéssemos dados mensais do indicador disponíveis até maio, adicionaríamos as observações de março, abril e maio à equação.
Em alguns casos, podemos ter uma variável principal trimestral ou mesmo anual, e talvez indicadores semanais ou mesmo diários. Isso resulta em um grande número de parâmetros a serem estimados, o que pode tornar as estimativas instáveis e aumentar o risco de ajuste excessivo do modelo aos dados. O modelo MIDAS Sparse Group Lasso resolve isso aplicando uma penalidade de Group Lasso ao ajustar o modelo.
Matematicamente, a penalidade do Grupo Lasso Sparse é um termo que é adicionado à função que é otimizada ao ajustar o modelo, para um modelo de regressão geral com pp coeficientes, ele pode ser escrito como
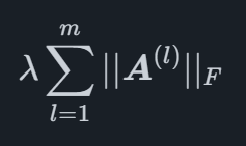
onde eX2 é o Frobenius norma de X que é definido como

para uma matriz X, em que o traçado é a soma das entradas diagonais de uma matriz quadrada. O benefício desse tipo de penalidade é que ele é capaz de reduzir grupos inteiros de coeficientes para zero, deixando outros grupos com valores diferentes de zero. Para o MIDAS Sparse Group Lasso, isso é usado para penalizar todos os atrasos de variáveis específicas como grupos, permitindo que o modelo selecione o efeito ideal que uma variável específica deve ter na variável principal.
O primeiro passo para ajustar um modelo MIDAS Sparse Group Lasso é dividir os dados em duas partes, chamadas de conjunto de treinamento e conjunto de teste.
A segunda etapa é ajustar o modelo usando o conjunto de observações de treinamento para uma variedade de diferentes λ valores. Esses modelos são então usados para criar previsões para os pontos de tempo no conjunto de teste. Esse processo é repetido várias vezes e o erro médio de previsão é usado como uma medida do desempenho do modelo, dados os diferentes valores de λ. A partir disso, o melhor valor que fornece as previsões mais precisas é selecionado.
Com o ideal λ valor selecionado, um modelo final que é ajustado a todos os dados é criado usando esse valor. Isso resulta em um modelo com uma penalidade ajustada para extrair o máximo poder preditivo dos dados, sem sobreajustar o modelo.

Fornecemos software de previsão automatizado que combina métodos acadêmicos de ponta com indicadores líderes específicos do mercado. Isso ajuda sua organização a atingir o mais alto nível de precisão de previsão.
© 2025 Indicio Technologies Todos os direitos reservados
