Il modello Mixed Data Sampling Sparse Group Lasso (MIDAS Sparse Group Lasso) è uno dei modelli a frequenza mista disponibili in Indicio. È simile al modello MIDAS Lasso, ma invece di utilizzare la penalità Lasso di base, utilizza un Lasso a gruppi sparsi adattato alla struttura dei dati.
Quando si prevede una serie temporale più lenta, ad esempio mensile, trimestrale o annuale, può essere un grande vantaggio utilizzare indicatori ad alta frequenza per fornire informazioni più aggiornate su come sta accadendo nell'economia.
Il modello MIDAS più elementare è quello denominato MIDAS senza restrizioni, che nel caso di una variabile principale trimestrale con un unico indicatore mensile assumerà la forma
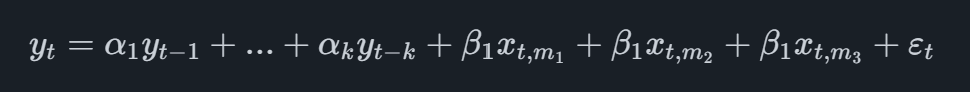
dove la variabile indicatore ha il pedice t,midove mimisi riferisce alla prima osservazione mensile disponibile. Ad esempio, se dovessimo prevedere il secondo trimestre e avessimo dati mensili dell'indicatore disponibili fino a maggio, aggiungeremmo all'equazione le osservazioni di marzo, aprile e maggio.
In alcuni casi possiamo avere una variabile principale trimestrale o addirittura annuale e forse indicatori settimanali o addirittura giornalieri. Ciò si traduce in un numero molto elevato di parametri da stimare, il che può rendere le stime instabili e aumentare il rischio di un adattamento eccessivo del modello ai dati. Il modello MIDAS Sparse Group Lasso risolve questo problema applicando una penalità Group Lasso durante l'adattamento del modello.
Matematicamente, la penalità Lasso Sparse Group è un termine che viene aggiunto alla funzione ottimizzata durante l'adattamento del modello, per un modello di regressione generale con pp coefficienti può essere scritto come
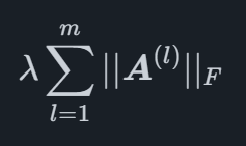
dove eX2 è il Frobenius norma di X che è definito come

per una matrice X, dove il tracetrace è la somma degli elementi diagonali di una matrice quadrata. Il vantaggio di questo tipo di penalità è che è in grado di ridurre interi gruppi di coefficienti a zero, lasciando altri gruppi con valori diversi da zero. Per il MIDAS Sparse Group Lasso questo viene utilizzato per poter penalizzare tutti i ritardi di variabili specifiche come gruppi, consentendo al modello di selezionare l'effetto ottimale che una determinata variabile dovrebbe avere sulla variabile principale.
Il primo passo verso l'adattamento di un modello MIDAS Sparse Group Lasso consiste nel suddividere i dati in due parti denominate training set e testing set.
Il secondo passaggio consiste nell'adattare il modello utilizzando il set di osservazioni di addestramento per una serie di diversi λ valori. Questi modelli vengono quindi utilizzati per creare previsioni per i punti temporali del set di test. Questo processo viene ripetuto più volte e l'errore di previsione medio viene utilizzato come misura delle prestazioni del modello in base a diversi valori di λ. Da qui viene selezionato il valore migliore che fornisce le previsioni più accurate.
Con l'ottimale λ valore selezionato, un modello finale adattato a tutti i dati viene creato utilizzando quel valore. Il risultato è un modello con una penalizzazione ottimizzata per estrarre la massima potenza predittiva dei dati, senza adattare eccessivamente il modello.

Forniamo un software di previsione automatizzato che unisce metodi accademici all'avanguardia con indicatori principali specifici del mercato. Questo aiuta la tua organizzazione a raggiungere il massimo livello di precisione delle previsioni.
© 2025 Indicio Technologies Tutti i diritti riservati
