El modelo Mixed Data Sampling Sparse Group Lasso (MIDAS Sparse Group Lasso) es uno de los modelos de frecuencia mixta disponibles en Indicio. Es similar al modelo de Lasso de MIDAS, pero en lugar de utilizar la penalización de Lasso básica, utiliza un Lasso de grupos dispersos que se adapta a la estructura de los datos.
Al pronosticar series temporales con un movimiento más lento, como una mensual, trimestral o anual, puede ser muy beneficioso utilizar indicadores de alta frecuencia para proporcionar información más actualizada sobre lo que está sucediendo en la economía.
El modelo MIDAS más básico es el denominado MIDAS sin restricciones, que en el caso de una variable principal trimestral con un solo indicador mensual adoptará la forma
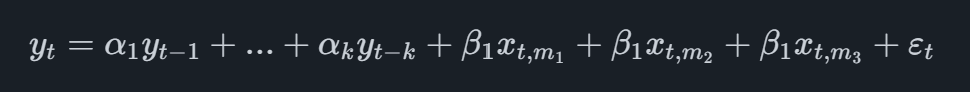
donde la variable indicadora tiene el subíndice t,midonde estoymise refiere a la i-ª última observación mensual disponible. Por ejemplo, si tuviéramos que hacer una previsión para el segundo trimestre y tuviéramos datos mensuales del indicador disponibles hasta mayo, añadiríamos a la ecuación las observaciones de marzo, abril y mayo.
En algunos casos, podemos tener una variable principal trimestral o incluso anual, y quizás indicadores semanales o incluso diarios. Esto hace que haya que estimar un gran número de parámetros, lo que puede hacer que las estimaciones sean inestables y aumentar el riesgo de que el modelo se ajuste demasiado a los datos. El modelo MIDAS Sparse Group Lasso resuelve este problema aplicando una penalización por lazo grupal al ajustar el modelo.
Matemáticamente, la penalización de Lasso Sparse Group es un término que se agrega a la función que se optimiza al ajustar el modelo, para un modelo de regresión general con pp coeficientes en los que se puede escribir
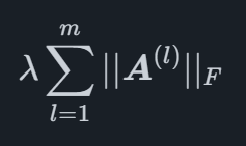
donde yX2 es el Frobenio norma de X que se define como

para una matriz X, donde la traza es la suma de las entradas diagonales de una matriz cuadrada. La ventaja de este tipo de penalización es que puede reducir grupos enteros de coeficientes a cero, dejando a otros grupos con valores distintos de cero. En el caso del lazo de grupos dispersos de MIDAS, se utiliza para poder penalizar todos los desfases de variables específicas como grupos, lo que permite al modelo seleccionar el efecto óptimo que una variable específica debería tener en la variable principal.
El primer paso para ajustar un modelo MIDAS Sparse Group Lasso es dividir los datos en dos partes, denominadas conjunto de entrenamiento y conjunto de pruebas.
El segundo paso es ajustar el modelo utilizando el conjunto de observaciones de entrenamiento para una serie de diferentes λ valores. Estos modelos se utilizan luego para crear pronósticos para los puntos temporales del conjunto de prueba. Este proceso se repite varias veces y el error de pronóstico promedio se usa como una medida del buen desempeño del modelo dados los diferentes valores de λ. A partir de ahí, se selecciona el mejor valor que proporciona las previsiones más precisas.
Con lo óptimo λ valor seleccionado, se crea un modelo final que se ajusta a todos los datos utilizando ese valor. Esto da como resultado un modelo con una penalización que se ajusta para extraer el máximo poder predictivo de los datos, sin sobreajustar el modelo.

Ofrecemos un software de pronóstico automatizado que combina métodos académicos de vanguardia con indicadores líderes específicos del mercado. Esto ayuda a su organización a alcanzar el nivel más alto de precisión en las previsiones.
© 2025 Iindicio Technologies Todos los derechos reservados
