As redes neurais visam imitar a forma como os neurônios do cérebro humano funcionam. O principal benefício sobre um modelo linear é que as redes neurais podem modelar relações não lineares mais complexas. A arquitetura geral consiste em uma camada de entrada, uma ou mais camadas ocultas e uma camada de saída de neurônios. Cada neurônio tem um coeficiente de peso come um coeficiente de polarização bi, junto com a entrada para o neurônio zi e uma função não linear, como a função sigmóide
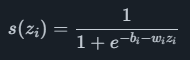
calcular um valor de saída s (zi)s(zi). Cada neurônio está conectado a todos os neurônios na camada seguinte, o que significa que um neurônio com várias entradas terá uma soma de vários wizitermos no expoente. O papel da função sigmóide aqui é freqüentemente chamado de função de ativação, e outras opções além do sigmóide são comumente usadas.
Ao adicionar várias camadas ocultas entre a entrada e a saída, é possível criar um modelo muito flexível. Com o modelo definido, os dados são passados por ele e o resultado é comparado com o valor real. Ao calcular o gradiente da função de erro, é possível ajustar os pesos e os vieses em uma direção que diminuirá o erro. Esse processo de otimização é chamado de gradiente descendente. Todo o processo de ajuste dos coeficientes aos dados costuma ser chamado formação o modelo, e os dados usados para fazer isso são chamados de dados de treinamento.
Com toda a flexibilidade oferecida, o maior desafio é evitar o ajuste excessivo do modelo aos dados, o que significa que o modelo se torna extremamente bom em descrever os dados de treinamento, mas, quando apresentado a novas observações, terá dificuldades. Resolver isso é uma questão de pesquisa aberta, mas existem muitas técnicas úteis.
Um exemplo é simplesmente passar uma amostra aleatória dos dados pelo modelo em cada iteração, resultando na técnica de otimização conhecida como gradiente descendente estocástico. Além disso, os dados geralmente são divididos em duas partes, uma usada para treinamento e outra usada para validação. O modelo nunca pode usar o conjunto de validação para treinamento, mas após um determinado número de iterações, o modelo é avaliado em relação ao conjunto de validação. Dessa forma, é possível interromper o processo de treinamento assim que o erro de validação começar a aumentar. A vantagem disso é que o modelo será treinado para ser o mais específico possível para os dados, permanecendo relevante para dados semelhantes não presentes no conjunto de treinamento.
Com um modelo grande o suficiente e dados de treinamento suficientes, é possível modelar estruturas muito complicadas. Exemplos disso são grandes modelos de linguagem que podem imitar a linguagem humana ao prever qual palavra tem maior probabilidade de vir depois da sequência atual que o modelo recebeu como entrada.
Para modelar uma série temporal Yt usando uma rede neural, o pp valores defasados Ainda−1, ... ,Ainda−psão usados como entradas e a rede neural é treinada para explicar o valor atual Yt. Uma previsão pode então ser criada usando Ainda, ... ,Ainda−p+1 como entradas para prever Ainda+1. Isso pode então ser repetido de forma recursiva usando o valor da previsão justa como entrada, criando uma previsão do comprimento desejado.
Um modelo de regressão linear pode ser ajustado aos dados de forma preditiva, por isso um único modelo quase sempre será suficiente. Uma rede neural pode acabar com muitos conjuntos diferentes de coeficientes decorrentes da natureza estocástica do SGD, entre outros fatores. Para minimizar a variação nos modelos, a Indicio cria vários modelos que são então calculados em média ao fazer as previsões.

Fornecemos software de previsão automatizado que combina métodos acadêmicos de ponta com indicadores líderes específicos do mercado. Isso ajuda sua organização a atingir o mais alto nível de precisão de previsão.
© 2025 Indicio Technologies Todos os direitos reservados
