Neurale netwerken zijn bedoeld om de manier waarop de neuronen in het menselijk brein werken na te bootsen. Het belangrijkste voordeel ten opzichte van een lineair model is dat neurale netwerken complexere niet-lineaire relaties kunnen modelleren. De totale architectuur bestaat uit een invoerlaag, een of meer verborgen lagen en een uitvoerlaag van neuronen. Elk neuron heeft een gewichtscoëfficiënt wien een biascoëfficiënt bi, samen met de input voor het neuron zi en een niet-lineaire functie zoals de sigmoïdfunctie
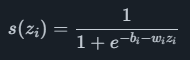
bereken een uitvoerwaarde s (zi)s(zi). Elk neuron is verbonden met alle neuronen in de volgende laag, wat betekent dat een neuron met meerdere ingangen een som heeft van meerdere wizitermen in de exponent. De rol van de sigmoïdfunctie wordt hier vaak een activeringsfunctieen andere opties naast de sigmoïde worden vaak gebruikt.
Door meerdere verborgen lagen toe te voegen tussen de invoer en uitvoer is het mogelijk om een zeer flexibel model te creëren. Als het model is gedefinieerd, worden er gegevens doorheen gestuurd en wordt het resultaat vergeleken met de werkelijke waarde. Door de gradiënt van de foutfunctie te berekenen, is het mogelijk om de gewichten en voortekenen in een richting aan te passen die de fout zal verminderen. Dit optimalisatieproces wordt gradiëntafdaling genoemd. Het hele proces van aanpassing van de coëfficiënten aan de gegevens wordt vaak opleiding het model en de gegevens die daarvoor worden gebruikt, worden aangeduid als trainingsgegevens.
Met alle flexibiliteit die wordt geboden, is de grootste uitdaging om te voorkomen dat het model te veel wordt afgestemd op de gegevens, wat betekent dat het model buitengewoon goed wordt in het beschrijven van de trainingsgegevens, maar wanneer het nieuwe observaties krijgt, zal het moeilijk zijn. Het oplossen hiervan is een open onderzoeksvraag, maar er bestaan veel bruikbare technieken.
Een voorbeeld is om bij elke iteratie gewoon een willekeurige steekproef van de gegevens door het model te laten gaan, wat resulteert in de optimalisatietechniek die wordt aangeduid als stochastische gradiëntafdaling. Verder worden de gegevens vaak opgesplitst in twee delen, een die wordt gebruikt voor training en een ander dat wordt gebruikt voor validatie. Het model mag de validatieset nooit gebruiken voor training, maar na een bepaald aantal iteraties wordt het model vergeleken met de validatieset. Op deze manier is het mogelijk om het trainingsproces te stoppen zodra de validatiefout begint toe te nemen. Het voordeel hiervan is dat het model wordt getraind om zo specifiek mogelijk te zijn voor de gegevens, terwijl het toch relevant blijft voor vergelijkbare gegevens die niet aanwezig zijn in de trainingsset.
Met een model dat groot genoeg is en voldoende trainingsgegevens is het mogelijk om zeer gecompliceerde structuren te modelleren. Voorbeelden hiervan zijn grote taalmodellen die menselijke taal kunnen nabootsen door te voorspellen welk woord het meest waarschijnlijk komt na de huidige reeks die het model als invoer heeft gekregen.
Om een tijdreeks Yt te modelleren met behulp van een neuraal netwerk, de pp achterblijvende waarden Yt−1, ... ,Yt−pworden gebruikt als input en het neurale netwerk wordt getraind om de huidige waarde Yt te verklaren. Vervolgens kan een voorspelling worden gemaakt met behulp van Yt, ... ,Yt−p+1 als input om te voorspellen Yt+1. Dit kan vervolgens op een recursieve manier worden herhaald met de juiste prognosewaarde als invoer, waardoor een voorspelling van de gewenste lengte wordt gemaakt.
Een lineair regressiemodel kan op een voorspellende manier aan gegevens worden aangepast, waardoor een enkel model bijna altijd voldoende is. Een neuraal netwerk kan eindigen met veel verschillende sets coëfficiënten die onder meer voortkomen uit de stochastische aard van SGD. Om de variantie in de modellen te minimaliseren, creëert Indicio een aantal modellen die vervolgens worden gemiddeld bij het maken van de voorspellingen.

We bieden geautomatiseerde voorspellingssoftware die geavanceerde academische methoden combineert met marktspecifieke toonaangevende indicatoren. Dit helpt uw organisatie om het hoogste niveau van voorspellingsnauwkeurigheid te bereiken.
© 2025 Indicio Technologies Alle rechten voorbehouden
