Les réseaux neuronaux visent à imiter le fonctionnement des neurones du cerveau humain. Le principal avantage d'un modèle linéaire est que les réseaux de neurones peuvent modéliser des relations non linéaires plus complexes. L'architecture globale comprend une couche d'entrée, une ou plusieurs couches cachées et une couche de sortie de neurones. Chaque neurone possède un coefficient de poids wiet un coefficient de biais bi, ainsi que l'entrée du neurone zi et une fonction non linéaire telle que la fonction sigmoïde
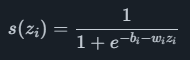
calculer une valeur de sortie s (zi)s(zip). Chaque neurone est connecté à tous les neurones de la couche suivante, ce qui signifie qu'un neurone avec plusieurs entrées aura une somme de plusieurs wizitermes de l'exposant. Le rôle de la fonction sigmoïde est souvent appelé ici fonction d'activation, et d'autres options autres que le sigmoïde sont couramment utilisées.
En ajoutant plusieurs couches cachées entre l'entrée et la sortie, il est possible de créer un modèle très flexible. Une fois le modèle défini, les données y sont transmises et le résultat est comparé à la valeur réelle. En calculant le gradient de la fonction d'erreur, il est possible d'ajuster les poids et les biais dans une direction qui réduira l'erreur. Ce processus d'optimisation est appelé descente en pente. L'ensemble du processus d'ajustement des coefficients aux données est souvent appelé formation le modèle et les données utilisées pour ce faire sont appelés données d'entraînement.
Avec toute la flexibilité offerte, le plus grand défi est d'éviter de surajuster le modèle aux données, ce qui signifie que le modèle devient extrêmement efficace pour décrire les données d'entraînement, mais qu'il aura du mal à décrire les données d'entraînement lorsqu'il sera présenté avec de nouvelles observations. Résoudre ce problème est une question de recherche ouverte, mais de nombreuses techniques utiles existent.
Par exemple, il suffit de faire passer un échantillon aléatoire des données dans le modèle à chaque itération, ce qui donne lieu à la technique d'optimisation appelée descente stochastique du gradient. De plus, les données sont souvent divisées en deux parties, l'une utilisée pour la formation et l'autre pour la validation. Le modèle n'est jamais autorisé à utiliser l'ensemble de validation pour l'entraînement, mais après un certain nombre d'itérations, le modèle est évalué par rapport à l'ensemble de validation. De cette façon, il est possible d'arrêter le processus de formation dès que l'erreur de validation commence à augmenter. L'avantage est que le modèle sera entraîné de manière à être aussi spécifique que possible aux données tout en restant pertinent pour des données similaires non présentes dans l'ensemble d'apprentissage.
Avec un modèle suffisamment grand et des données d'entraînement suffisantes, il est possible de modéliser des structures très complexes. À titre d'exemple, citons les grands modèles de langage qui peuvent imiter le langage humain en prédisant quel mot est le plus susceptible de venir après la séquence actuelle que le modèle a reçue en entrée.
Pour modéliser une série chronologique Yt à l'aide d'un réseau neuronal, le pp valeurs décalées Yt−1, ... ,Yt−psont utilisés comme entrées et le réseau neuronal est entraîné pour expliquer la valeur actuelle Yt. Une prévision peut ensuite être créée en utilisant Yt, ... ,Yt−p+1 comme entrées pour prédire Yt+1. Cela peut ensuite être répété de manière récursive en utilisant la juste valeur de prévision comme entrée, créant ainsi une prévision de la longueur souhaitée.
Un modèle de régression linéaire peut être ajusté aux données de manière prédictive, ce qui explique pourquoi un seul modèle sera presque toujours suffisant. Un réseau de neurones peut se retrouver avec de nombreux ensembles de coefficients provenant, entre autres, de la nature stochastique du SGD. Pour minimiser la variance des modèles, Indicio crée un certain nombre de modèles qui sont ensuite moyennés lors de l'établissement des prévisions.

Nous fournissons un logiciel de prévision automatisé qui associe des méthodes académiques de pointe à des indicateurs avancés spécifiques au marché. Cela permet à votre organisation d'atteindre le plus haut niveau de précision des prévisions.
© 2025 Indicio Technologies Tous droits réservés
