Sieci neuronowe mają na celu naśladowanie sposobu działania neuronów w ludzkim mózgu. Główną zaletą w stosunku do modelu liniowego jest to, że sieci neuronowe mogą modelować bardziej złożone relacje nieliniowe. Ogólna architektura składa się z warstwy wejściowej, jednej lub więcej ukrytych warstw i wyjściowej warstwy neuronów. Każdy neuron ma współczynnik wagowy Wii współczynnik odchylenia bi, wraz z wejściem do neuronu zi i funkcją nieliniową, taką jak funkcja esicy
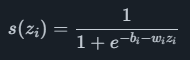
obliczyć wartość wyjściową s (zi)s(zi). Każdy neuron jest połączony ze wszystkimi neuronami w następnej warstwie, co oznacza, że neuron z wieloma wejściami będzie miał sumę wielu wiziterminy w wykładniku. Rola funkcji esicy jest tutaj często nazywana funkcja aktywacji, i inne opcje oprócz esicy są powszechnie stosowane.
Dodając wiele ukrytych warstw między wejściem a wyjściem, możliwe jest stworzenie bardzo elastycznego modelu. Po zdefiniowaniu modelu dane są przez niego przekazywane, a wynik jest porównywany z rzeczywistą wartością. Obliczając gradient funkcji błędu, możliwe jest dostosowanie wag i uprzedzeń w kierunku, który zmniejszy błąd. Ten proces optymalizacji nazywa się opadaniem gradientowym. Cały proces dostosowywania współczynników do danych jest często nazywany trening model, a dane wykorzystane w tym celu określane są jako dane szkoleniowe.
Przy całej oferowanej elastyczności największym wyzwaniem jest uniknięcie nadmiernego dopasowania modelu do danych, co oznacza, że model staje się niezwykle dobry w opisywaniu danych treningowych, ale po przedstawieniu nowych obserwacji będzie miał trudności. Rozwiązanie tego jest otwartym pytaniem badawczym, ale istnieje wiele przydatnych technik.
Jednym z przykładów jest po prostu przekazanie losowej próbki danych przez model przy każdej iteracji, co skutkuje techniką optymalizacji określoną jako stochastyczne opadanie gradientu. Ponadto dane są często podzielone na dwie części, jedną, która jest wykorzystywana do szkolenia, a drugą służy do walidacji. Model nigdy nie może używać zestawu walidacji do szkolenia, ale po określonej liczbie iteracji model jest oceniany w stosunku do zestawu walidacji. W ten sposób możliwe jest zatrzymanie procesu szkolenia, gdy tylko błąd walidacji zacznie narastać. Zaletą tego jest to, że model zostanie przeszkolony tak, aby był jak najbardziej specyficzny dla danych, jednocześnie pozostając istotny dla podobnych danych nieobecnych w zestawie szkoleniowym.
Dzięki wystarczająco dużemu modelowi i wystarczającym danom szkoleniowym możliwe jest modelowanie bardzo skomplikowanych struktur. Przykładami tego są duże modele językowe, które mogą naśladować język ludzki, przewidywając, które słowo najprawdopodobniej pojawi się po bieżącej sekwencji, którą model otrzymał jako dane wejściowe.
Aby modelować szeregi czasowe Yt za pomocą sieci neuronowej, pp wartości opóźnione Yt−1, ... ,Yt−psą używane jako wejścia, a sieć neuronowa jest szkolona w celu wyjaśnienia aktualnej wartości Yt. Prognozę można następnie utworzyć za pomocą Yt, ... ,Yt−p+1 jako dane wejściowe do przewidywania Yt+1. Można to następnie powtórzyć w sposób rekurencyjny, używając wartości właśnie prognozy jako danych wejściowych, tworząc prognozę o pożądanej długości.
Model regresji liniowej można dopasować do danych w sposób predykcyjny, dlaczego jeden model prawie zawsze będzie wystarczający. Sieć neuronowa może zawierać wiele różnych zestawów współczynników wynikających między innymi ze stochastycznej natury SGD. Aby zminimalizować wariancję w modelach, Indicio tworzy szereg modeli, które są następnie uśredniane podczas sporządzania prognoz.

Zapewniamy oprogramowanie do automatycznego prognozowania, które łączy najnowocześniejsze metody akademickie z wiodącymi wskaźnikami specyficznymi dla rynku. Dzięki temu Twoja organizacja osiąga najwyższy poziom dokładności prognozowania.
© 2025 Indicio Technologies Wszelkie prawa zastrzeżone
